LSM-Treeの書き込み性能を探る
LSM-Tree は書き込みヘビーなワークロードを捌くデータベースエンジンで広く採用されている。本記事ではその書き込み性能がどのように構成されているのかを探ってみる。内容は基本的に RocksDB をベースにしているため、一般的な LSM-Tree 全体に当てはまるわけではないことに注意。
LSM-Tree の書き込みの流れ
LSM-Tree の一般的な基本構造については世の中に解説記事がたくさんあるので省略し、ここでは書き込み性能に関わる部分に注目する。
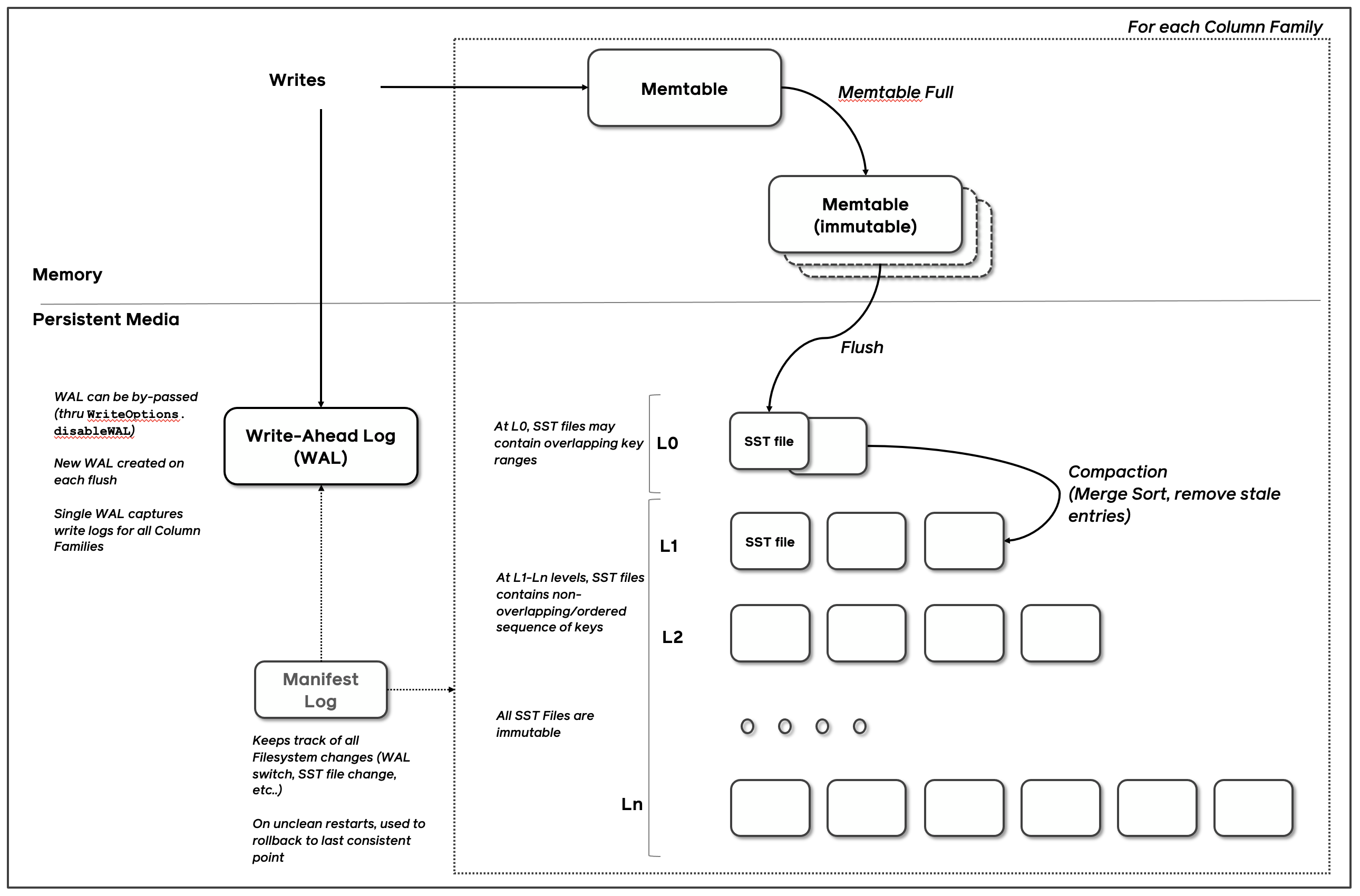
引用元: https://github.com/facebook/rocksdb/wiki/RocksDB-Overview/a13a098ad464b1892ace718c391d2fc7a5266211
図は RocksDB の Wiki に掲載されているものであるが、
- 書き込みは MemTable と WAL に対して行われる
- MemTable はメモリ上のデータ構造
- MemTable が一定サイズに達すると、immutable としてマークされ、新しい MemTable が作成される
- immutable な MemTable はバックグラウンドで SSTable としてフラッシュされる
- フラッシュに合わせて Manifest Log も書き込まれ、SSTable の情報が管理される
RocksDB の書き込み性能に関わる要素
書き込みは MemTable と WAL に対して行われる。MemTable はメモリ上のデータ構造であるため、基本的には高速に書き込みが可能である。対して WAL はディスクへの書き込みが発生する。
RocksDB は設定によって WAL の書き込みをバッファリングできるが、デフォルトではバッファリングせずに WAL の書き込みごとにフラッシュされる1。ここで言うフラッシュは OS キャッシュへの書き込みであり、DB の耐久性文脈でしばしば登場する fsync2 までする場合に比べて高速ではあるが、やはりメモリ上の操作に比べるとオーバーヘッドが大きい。
また MemTable が一定サイズに達すると immutable としてマークされ SSTable としてフラッシュされるが、フラッシュ自体はバックグラウンドで実施されるため、こちらは書き込み性能への直接的な影響は小さい。
つまり、書き込み性能は主に WAL のフラッシュ、MemTable へのエントリの追加、一定サイズに達した際の MemTable のアトミックな切り替えによって構成されていると考えられる。
RocksDB の書き込み性能
RocksDB の Wiki の Performance Benchmarks にランダムな順序でのキーの bulk load 性能のベンチマーク結果が掲載されている。それを見ると書き込み性能は概ね 1M ops/sec 程度であることが分かる。
抜粋:
| Version | ops/sec | mb/sec |
|---|---|---|
| 7.2.2 | 1,003,732 | 402.0 |
では、実際に手元でも試してみる。環境は以下。
Chip: Apple M1 Max
Total Number of Cores: 10 (8 performance and 2 efficiency)
Memory: 64 GB$ brew list --versions rocksdb
rocksdb 10.7.5_1ベンチマークは Rust の Criterion クレートを使って以下のように実装。
fn benchmark_bulkload_random(c: &mut Criterion) {
let mut group = c.benchmark_group("bulkload_random");
group.warm_up_time(Duration::from_secs(1));
group.measurement_time(Duration::from_secs(3));
group.sample_size(10);
// 1エントリ = 116 bytes, 64MB = 約578,524 keys
// 100k keys: 約11.1 MB (flush無し)
// 600k keys: 約69.6 MB (flush 1回)
// 3M keys: 約348 MB (flush 5回)
for num_keys in [100_000, 600_000, 3_000_000].iter() {
// スループットを bytes/sec で測定
let bytes_per_op = (KEY_SIZE + VALUE_SIZE) as u64;
group.throughput(Throughput::Bytes(*num_keys * bytes_per_op));
group.bench_with_input(
BenchmarkId::new("keys", num_keys),
num_keys,
|b, &num_keys| {
let mut iteration = 0;
b.iter_batched(
|| {
// ランダムな順序でキーを生成
let mut keys: Vec<u64> = (0..num_keys).collect();
// シンプルなシャッフル(Fisher-Yates)
for i in (1..keys.len()).rev() {
let j = (i as u64 * 48271 % 2147483647)
as usize % (i + 1);
keys.swap(i, j);
}
iteration += 1;
let db_path = format!(
"/tmp/rocksdb_bench_random_{}",
iteration,
);
let db = setup_rocksdb(&db_path);
(db, db_path, keys, generate_value(VALUE_SIZE))
},
|(db, db_path, keys, value)| {
let mut write_opts = WriteOptions::default();
// 単純なPut操作(batch_size=1相当)
for key_num in keys {
let key = generate_key(key_num);
db.put_opt(
&key,
&value,
&write_opts,
).expect("Failed to put");
}
drop(db);
let _ = std::fs::remove_dir_all(db_path);
},
BatchSize::LargeInput,
);
},
);
}
group.finish();
}やっていることとしては、
- ランダムな順序でキーを生成
- 100k keys: 約11.1 MB (flush無し)
- 600k keys: 約69.6 MB (flush 1回)
- 3M keys: 約348 MB (flush 5回)
- 単純に
db.putを繰り返し呼び出して書き込む
結果は以下。
| Keys | Time | Throughput | Operations/sec |
|---|---|---|---|
| 100,000 | 454.32 ms | 24.35 MiB/s | 220,126 ops/s |
| 600,000 | 3.09 s | 21.46 MiB/s | 194,175 ops/s |
| 3,000,000 | 15.74 s | 21.08 MiB/s | 190,596 ops/s |
公式の結果に比べて 1/5 程度の ops/s しか出ていない。これは bulk load のベンチマークが一括書き込みに最適化するためにパラメータを変更していることが影響している3。
パラメータの影響を 100,000 件の key 数で軽く見てみた結果は以下。
| Parameter | Description | Impact |
|---|---|---|
sync | WAL 書き込みごとに fsync をするかどうかの設定 | 1 にすると 240 ops/sec まで落ちるが、デフォルトは 0 (=耐久性なし)なので設定は同等。 |
disable_wal | WAL を無効化するかどうかの設定 | 1 にすると 4x 速くなりインパクト大。 |
disable_auto_compactions | 自動コンパクションを無効化するかどうかの設定 | 誤差(key 数が少ないためだと思われる) |
allow_concurrent_memtable_write | 複数スレッドからの MemTable 書き込みを許可するかどうかの設定 | 誤差(シングルスレッドでの書き込みのため) |
ということで、fsync までしてなくても WAL の書き込みがボトルネックになっていることが分かる。OS キャッシュへの書き込みとはいえオーバーヘッドが大きいことが分かった4。
以下のように disable_wal = true を設定して、もう一度ベンチマークを実行する。
let mut write_opts = WriteOptions::default();
+ write_opts.disable_wal(true);
// 単純なPut操作(batch_size=1相当)
for key_num in keys {
let key = generate_key(key_num);
db.put_opt(
&key,
&value,
&write_opts,
).expect("Failed to put");
}| Keys | Time | Throughput | Operations/sec |
|---|---|---|---|
| 100,000 | 139.92 ms | 79.06 MiB/s | 714,655 ops/s |
| 600,000 | 1.05 s | 63.12 MiB/s | 570,545 ops/s |
| 3,000,000 | 4.72 s | 70.29 MiB/s | 635,158 ops/s |
公式の 1M ops/sec には届かないものの、そこそこの性能が出るようになった。
RocksDB の性能を見るのはここまでにする。結果から分かったこととしては、
- MemTable への書き込みと非同期での SSTable のフラッシュだけであれば 〜1M ops/sec 程度の性能が出る
- WAL 書き込み時に毎回フラッシュをすると 1/3〜1/4 程度に性能が落ちる
- (書き込みごとに耐久性を持たせるために fsync をするとさらに大幅に性能が落ちる)
ということになる。
単なるログ出力処理の性能を見る
次に単純なログ出力処理の性能を見てみる。一応 LSM-Tree の書き込みパスを意識して以下のような構成とする。
- メモリ上のバッファにログエントリを追加
- バッファが一定サイズに達したらimmutable 化し、新しいバッファを作成
- バックグラウンドで immutable なバッファをファイルに書き出す
実装イメージは以下。
/// ログエントリ
#[derive(Clone)]
pub struct LogEntry {
pub key: Vec<u8>,
pub value: Vec<u8>,
}
/// Mutable なバッファ
struct MemTable {
entries: Vec<LogEntry>,
size: usize,
}
impl MemTable {
fn new() -> Self {
Self {
entries: Vec::new(),
size: 0,
}
}
fn put(&mut self, key: Vec<u8>, value: Vec<u8>) {
let entry_size = key.len() + value.len();
self.entries.push(LogEntry { key, value });
self.size += entry_size;
}
fn size(&self) -> usize {
self.size
}
fn is_empty(&self) -> bool {
self.entries.is_empty()
}
}
pub struct WritePath {
/// 現在のmutableバッファ
memtable: Arc<Mutex<MemTable>>,
/// Immutableバッファを送信するチャネル (bounded channelでwrite stallを実現)
flush_sender: Option<SyncSender<MemTable>>,
/// バックグラウンドスレッドのハンドル
flush_thread: Option<JoinHandle<()>>,
}
impl WritePath {
// ...
/// キーと値を書き込む
///
/// immutable MemTableの数が上限に達している場合、
/// フラッシュが完了するまで書き込みがブロックされる(write stall)
pub fn put(&self, key: Vec<u8>, value: Vec<u8>) -> std::io::Result<()> {
let mut memtable = self.memtable.lock().unwrap();
memtable.put(key, value);
// サイズ閾値を超えたらフラッシュ
// このsend()でブロックする可能性がある(write stall)
if memtable.size() >= self.size_threshold {
self.freeze_memtable(&mut memtable)?;
}
Ok(())
}
/// 現在のmemtableをimmutable化して新しいmemtableを作成
fn freeze_memtable(&self, memtable: &mut std::sync::MutexGuard<MemTable>) -> std::io::Result<()> {
// 古いmemtableを取り出し、新しいmemtableと交換
let old_memtable = std::mem::replace(&mut **memtable, MemTable::new());
// バックグラウンドスレッドに送信
if !old_memtable.is_empty() {
if let Some(sender) = &self.flush_sender {
sender.send(old_memtable)
.map_err(|e| std::io::Error::new(std::io::ErrorKind::Other, e.to_string()))?;
}
}
Ok(())
}
/// バックグラウンドフラッシュスレッドを生成
fn spawn_flush_thread(
rx: Receiver<MemTable>,
data_dir: PathBuf,
counter: Arc<Mutex<usize>>,
) -> JoinHandle<()> {
thread::spawn(move || {
while let Ok(memtable) = rx.recv() {
if let Err(e) = Self::write_sstable(&data_dir, &memtable, &counter) {
eprintln!("Failed to write SSTable: {}", e);
}
}
})
}
/// SSTableファイルに書き出す
fn write_sstable(
data_dir: &Path,
memtable: &MemTable,
counter: &Arc<Mutex<usize>>,
) -> std::io::Result<()> {
let file_num = {
let mut c = counter.lock().unwrap();
let num = *c;
*c += 1;
num
};
let file_path = data_dir.join(format!("{:06}.sst", file_num));
let file = OpenOptions::new()
.write(true)
.create(true)
.truncate(true)
.open(file_path)?;
// BufWriterでバッファリング(デフォルト8KB)
let mut writer = BufWriter::new(file);
// シンプルなフォーマット: [key_len: u32][key][value_len: u32][value]
for entry in &memtable.entries {
writer.write_all(&(entry.key.len() as u32).to_le_bytes())?;
writer.write_all(&entry.key)?;
writer.write_all(&(entry.value.len() as u32).to_le_bytes())?;
writer.write_all(&entry.value)?;
}
// flushでバッファをディスクに書き出す(fsyncはしない)
writer.flush()?;
Ok(())
}
}| Keys | Time | Throughput | Operations/sec |
|---|---|---|---|
| 100,000 | 31.11 ms | 355.59 MiB/s | 3,216,844 ops/s |
| 600,000 | 192.53 ms | 344.76 MiB/s | 3,118,997 ops/s |
| 3,000,000 | 735.48 ms | 451.24 MiB/s | 4,079,638 ops/s |
4M ops/sec 程度の性能が出た。
素朴な実装で世の中の高速ロガーと比べると劣るが、ベースラインの参考性能としてはまずまずの値になった。
MemTable を SkipList にして性能を見る
次に MemTable の実装を Vec から SkipList に変更して性能を見てみる。SkipList は LSM-Tree でよく使われるデータ構造であり、RocksDB でもデフォルトで採用されている5。
SkipList 版の実装には crossbeam-skiplist クレートを使用する。 変更は主に MemTable 部分のみ。
+ use crossbeam_skiplist::SkipMap;
/// Mutable なバッファ
struct MemTable {
- entries: Vec<LogEntry>,
+ entries: SkipMap<Vec<u8>, Vec<u8>>,
size: usize,
}| Keys | Time | Throughput | Operations/sec |
|---|---|---|---|
| 100,000 | 116.03 ms | 95 MiB/s | 862,000 ops/s |
| 600,000 | 1.25 s | 53 MiB/s | 480,000 ops/s |
| 3,000,000 | 4.72 s | 70 MiB/s | 635,000 ops/s |
SkipList にしたところ Vec に比べて大幅に性能が落ちた。3M keys の場合で6分の1程度になっている。
単に Vec と SkipMap に対して put を繰り返すベンチマークを取ってみたところ、1/4 〜 1/10 程度の性能差があったため、MemTable 部分の実装が書き込み性能に大きく影響していることが分かる。
書き込みはシングルスレッドで行っているが crossbeam-skiplist はマルチスレッドでの書き込みもサポートしており、そのためのオーバーヘッドが載っている可能性もある(ただ、他の SkipList 実装も試してみたものの更に遅かった)。
まとめ
今回試したシングルスレッドでの 3M keys の書き込みにおける各実装の書き込み性能(ops/sec)を以下にまとめる。
xychart-beta
title "書き込み性能の比較 (K ops/sec)"
x-axis ["RocksDB default", "RocksDB (WAL無効)", "Vec log", "SkipList log"]
y-axis "" 0 --> 4500
bar [191, 635, 4080, 635]
Warning
RocksDB と簡易実装では機能面が大きく異なるため、apples-to-apples の比較ではない。あくまで書き込みパスの各要素が性能にどの程度寄与するかを把握するための参考値として並べている。
LSM-Tree の書き込み性能は主に MemTable で採用しているデータ構造で決まることが分かった。
今回の簡易的な実装では WAL 書き込みは省略したが、単なる Vec ベースのバッファ実装であればボトルネックにはならないと考えられるが、毎回フラッシュしたり書き込みごとに耐久性を持たせるために fsync すると大幅に性能は落ちる。RocksDB は利用側にこのあたりの制御を委ねる形となっている。
また本来 LSM-Tree では読み書き両方の性能をバランスを取るために Compaction 処理や追加のインデックス構造の管理が重要になるが、今回は LSM-Tree を知る第一歩として純粋な書き込み性能を掴むところまでにとどめた(そもそもこの簡易的な実装は log structured ではなく merge もしておらず tree 構造でもないので、到底 LSM-Tree とは呼べないが…)。LSM-Tree の技術的な面白さはこの先にもたくさんあるので、また別の機会に掘り下げてみたい。
Compaction については最近読んだ論文で Rethinking The Compaction Policies in LSM-trees(SIGMOD 2025)というものがあり面白かったので、興味がある方はぜひ。
Note
今回の簡易実装やベンチマークは https://github.com/hmarui66/learning-lsm-write-path で公開しているので、もし間違いや改善点などあれば Issue 等で教えてください
Footnotes
-
デフォルトのオプション設定では
manual_wal_flush = falseとなっており、WAL 書き込みごとに flush がされる動作となる。 ↩ -
WAL の sync(≠flush) ついては RocksDB の Wiki の WAL Performanceに記載がある。ちなみに sync 時に呼ばれるのはデフォルトで fdatasync なので、ファイルシステムによっては sync してもクラッシュセーフではない ↩
-
pwriteの性能を簡単に測定したところ、300K ops/sec だったので、disable_wal=false の場合の RocksDB の書き込み性能に近い値となった ↩ -
SkipList 以外にも HashLinkList, HashSkipList, Vector などの実装が用意されている ↩