PlanetScale の PostgreSQL ベンチマーク記事を読み解く
先日 MySQL に特化していた PlanetScale が PostgreSQL もサポートし、また近い将来 Nova という Vitess 同等のスケーリングソリューションも提供するという発表があった。
https://planetscale.com/blog/planetscale-for-postgres
発表では、競合サービスとのパフォーマンス比較を実施したことについても触れられており、結果は Benchmarking Postgresという記事にまとめられている。
比較対象となっているのは、Amazon Aurora, Google AlloyDB, Neon/Lakebase, Supabase, CrunchyData, TigerData, Heroku Postgres で、よくやったなーという印象1
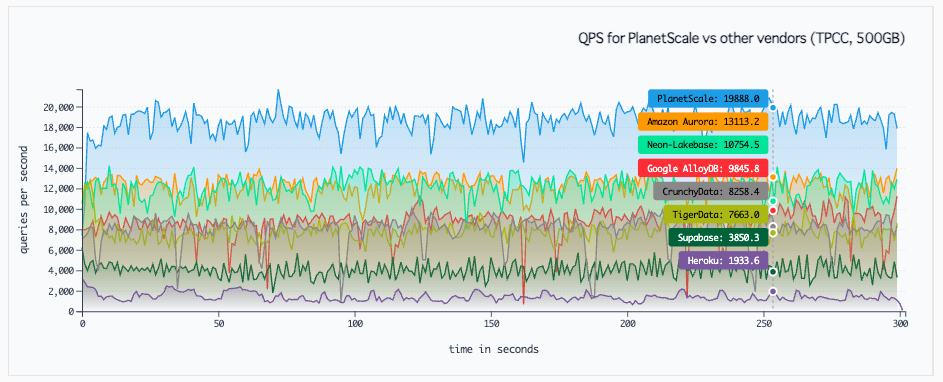
この PlanetScale のベンチマーク記事、そして記事に対するリアクションについて、個人的に学びが多かったのでその辺りをつらつら書いておく。
PlanetScale のベンチマーク記事の概要
https://planetscale.com/blog/benchmarking-postgres
この記事には、ベンチマークの作成、実行、評価に使用できる社内ツール「Telescope」を開発し、各社の DB をベンチマークしたことについて書かれている。
また「ベンチマークとは」についても触れられており、どんなベンチマークにも欠点があるが適切に実施されていれば色々な質問に応えるために有用、とある。
色々な質問というのは具体的には、レイテンシ、典型的な OLTP 負荷下でのパフォーマンス(TPS, QPS)、高い読み取り/書き込み下でのパフォーマンス(IOPS, キャッシュ)、一定のパフォーマンスを達成するためのコスト(価格:パフォーマンス比)など。
これらを明らかにするため、利用するベンチマークは以下の3つ。
- Latency: シンプルな query-path レイテンシのベンチマーク
- 同じ region 内の別インスタンスから
SELECT 1;を繰り返し実行
- 同じ region 内の別インスタンスから
- TPCC: Percona 社が開発した TPCC に似たベンチマーク
- OLTP Read-only: 読み取り専用の sysbench ワークロード
公平性のため、各社の DB について同等の(一部 PlanetScale が不利な) vCPU, RAM のインスタンスを作成し、ストレージに関しても IOPS を設定できるものは調整をしたとのこと。
個々の結果は別のページにまとめられており、例えば Amazon Aurora と比較したものは以下。
https://planetscale.com/benchmarks/aurora
その他の DB との比較結果も合わせた主張は、パフォーマンス & コストも PlanetScale の PostgreSQL が圧倒的に優れていた、だった。
この記事を読むのに必要な知識: TPCC に似たベンチマーク
ベンチマークの中で「Percona 社が開発した TPCC に似たベンチマーク」というのが出てくるが、これは Percona-Lab/sysbench-tpcc という OSS として公開されているもの。
README には以下のように書いてある。2
これはTPCCワークロードの実装ではありません。TPCCライクなものであり、TPCC仕様のクエリとスキーマのみを使用します。必要な「キー入力時間」は考慮されておらず、ウェアハウス数に応じて拡張可能なオープンループベンチマークではなく、固定データセットに対するクローズドループ競合ベンチマークとして機能します。また、TPCC仕様の他の複数の要件も考慮されていません。ベンダー間の比較のためにTPC-Cの結果を生成するためにsysbench-tpccを使用しないでください。または、TPCCライクな性質に関する同様の免責事項を添付してください (Google 翻訳)
ということで、まず TPC-C について知る必要があるが、それについてはnikezono さんの TPC-C についてのメモがとても分かりやすい。
メモの冒頭に書かれている箇所を抜き出す。
トランザクション処理性能評議会(Transaction processing Performance Council, TPC)の定める ベンチマーク のひとつ. 物流システムを模したベンチマークになっている.
ざっくりいうと、Warehouse, Customer, Item, Stock, Order, … などのテーブルに対して読み/書きのクエリを実行していってパフォーマンスを計測するためのベンチマーク。
細かいスペックは 132 ページに及ぶ PDF として公開されている。
https://www.tpc.org/tpc_documents_current_versions/pdf/tpc-c_v5.11.0.pdf
さて、Percona-Lab/sysbench-tpcc の README に戻る。「これはTPCCワークロードの実装ではありません」から始まり、続いて TPC-C のスペックを満たしてないことについて書かれている。
満たしていないことを再掲すると、
必要な「キー入力時間」は考慮されておらず、ウェアハウス数に応じて拡張可能なオープンループベンチマークではなく、固定データセットに対するクローズドループ競合ベンチマークとして機能します。
とある。
まず「キー入力時間」だが、これは TPC-C のスペックで定められているもので、以下のような流れで人間がシステムを操作することをエミュレートして、トランザクションの実行ペースを調整するための待ち時間のことである。
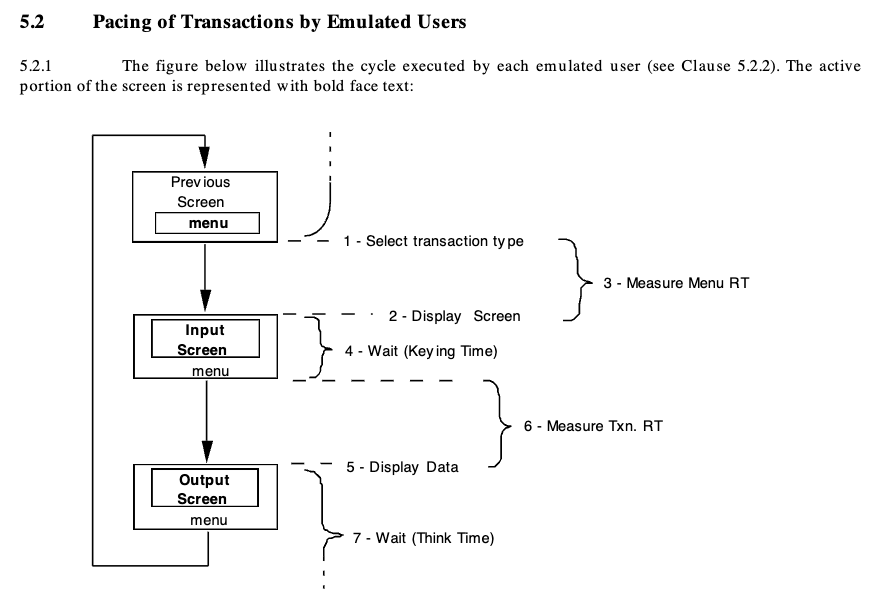
キー入力時間(Keying Time)の他にも思考時間(Think Time)も必要で、これらについて各種操作ごとに取るべき秒数が提示されている。
次に「ウェアハウス数に応じて拡張可能なオープンループベンチマークではなく、固定データセットに対するクローズドループ競合ベンチマークとして機能する」について。
正直ここは自信が無いところだが、Hacker News にあったコメントを参考にしつつ自分なりに理解したことを書いておく。
TPC-C は以下のように Warehouse をベースにして各エンティティの数が決まる。
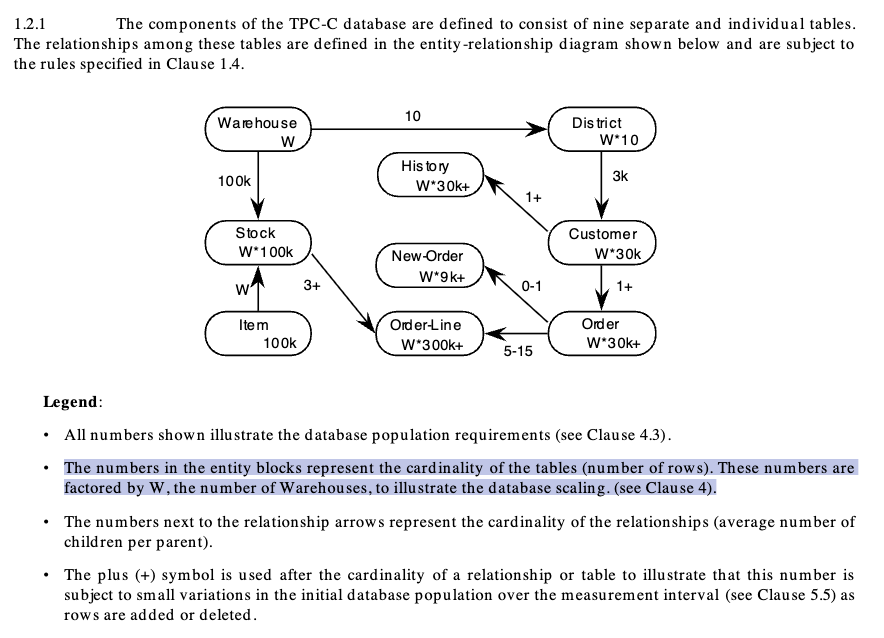
つまり Warehouse 数が 2 倍になると Customer も 2 倍になり、Order 数も2倍になる。
また、スペックの 2.4.1.5 に以下のようなことが書いてあり、
With an average of 10 items per order, approximately 90% of all orders can be supplied in full by stocks from the home warehouse.
- Order のうち平均 90 % は単一の Warehouse で供給可能なもの
- 10 % は複数の Warehouse の在庫が関係するもの
とすることで、一定頻度で複数 Warehouse にまたがるトランザクションを発行させる決まりになっている。
Warehouse 数を徐々に増やしていくことでそれに応じて Order 数も増えるが、90 % は上記の通り単一の Warehouse 内の在庫の調整が可能でデータの競合は少ないため(とはいえ同一 Item の在庫の割当てなど競合は起こるはず)、スループットはスケールしていく。
ただ DB の処理の限界に近づいてトランザクションが滞留し始めると、10 % の複数 Warehouse にまたがるトランザクションによって競合が雪だるま式に発生し、パフォーマンスが急激に低下することになる(ということのはず)。
それに対して Percona-Lab/sysbench-tpcc の場合は、ベンチマーク実行前の準備フェーズで固定数の Warehouse と関連データを登録した上で、ベンチマーク実行時には “Keying Time” 無しでレスポンスが返ったら即座に次のトランザクションを発行する。そのため現実的なシナリオとはかけ離れた「ロック競合が多発する中でどれくらいスループットを出せるか」ということを計測する形になる(ということのはず)。
Percona-Lab/sysbench-tpcc のベンチマーク結果は有用なのか
名前についている TPC-C とは似て非なるものであり、ちゃんと TPC-C のスペックに準拠したベンチマークツールでの計測結果と比較する意味はないことは確実だが、Percona-Lab/sysbench-tpcc を用いた同条件での結果に関しては比較可能で一定参考にはなる認識。
参考にするといっても、ひどく結果が悪いものを篩にかけるくらいの使い方で、結果が良くても DB 選定の決め手にはしないかなというところ。
PlanetScale のベンチマーク記事に対するリアクション
比較対象となっていた Neon はローカルファイルキャッシュを用いた構成にすると PlanetScale に迫るスループットになるという記事を出していた(かなり割高にはなる)。
https://neon.com/blog/separation-of-storage-and-compute-perf
また去年 Supabase に join した OrioleDBは Supabase インスタンス上の PostgreSQL のストレージエンジンを OrioleDB に変えた結果を公表していた(こちらも割高構成)。
https://www.orioledb.com/blog/orioledb-beta12-benchmarks
もう一つ、PlanetScale の記事の比較対象ではないが、PostgreSQL のマネージドサービスを提供する Xata3の記事も紹介。TPC-C や Percona-Lab/sysbench-tpcc についての軽い説明もある。PlanetScale を上回るベンチマーク結果を出しつつ、その理由(ベンチマークとリソースに合わせて PostgreSQL の設定を調整しているなど)も書かれている。
https://xata.io/blog/reaction-to-the-planetscale-postgresql-benchmarks
最後に
ベンチマークいまいち分からないので 読解いやな法則: にわかな奴ほど語りたがるを参考に、にわか駆動で書いてみたが、結構良かった。今後も活用していきたい。
Footnotes
-
ベンチマーク結果の公表を制限しているベンダーは多い印象だった。ただ例えばAWSのサービス条件(pdf)を見ると「1.8. 貴社は本サービスのベンチマークテストや比較テスト、評価それぞれ「ベンチマークテスト」と呼び ますを行うことができます。本サービスのベンチマークテストを貴社が実施もしくは開示する場合、また は実施もしくは開示を第三者に指示もしくは許可する場合、貴社は i かかるベンチマークテストの再現 に必要な情報をすべての開示情報に含め、かつ当社にも開示し、また、ii ベンチマークテストに貴社の 製品またはサービスに適用される条件についてどのような制限があってもそれにもかかわらず、貴社 の製品またはサービスのベンチマークテストを当社が実施しその結果を開示することに同意します。」とあり、今回のように再現のための情報も公開していたら問題は無さそう。 ↩
-
実は抜き出した箇所は PlanetScale が記事を出した後に追記されている。https://github.com/Percona-Lab/sysbench-tpcc/pull/53 ↩
-
まだクローズドベータだが、Neon と同種のブランチ機能を有しており、Compute と Storage の分離方式も独特で興味深い。Compute ではバニラ PostgreSQL を用いつつ独自の技術の分散ストレージと組み合わせる構成とのこと。https://xata.io/blog/xata-postgres-with-data-branching-and-pii-anonymization ↩